
Adaptive Computing Software
NLR's adaptive computing software enables a robust and simple-to-use approach for simulating and modeling engineering designs for a range of technologies.
Simulations play a key role in engineering design, but often high-fidelity simulations that provide an accurate representation of physics require significant computational resources for routine use. Low-fidelity models—less expensive to perform—are less accurate.
The adaptive computing software package provides several generalized capabilities:
- Easily transform one-off simulations into an automated capability for
launching simulation ensembles and train efficient, uncertainty-aware
surrogate models. Model fidelity hierarchies can be generated on the
fly, and strategies are provided to select the fidelity at every stage
that best informs decision making and control strategies.
- Strategic use of data acquisition resources based on uncertainty
quantification from surrogate models (e.g., Gaussian Processes, and
Bayesian neural networks) and a prescribed acquisition budget,
leveraging NLR's HERO: Hybrid Environment Research and Operations
infrastructure.
- Automated control of hardware assets, such as
those within ARIES: Advanced Research on Integrated Energy Systems, to
accelerate exploration of an array of scenarios in a modular and
scalable fashion.
- Closed-loop, autonomous experimentation via remote virtual servers. This capability lays the foundation for a network of laboratory instruments each integrated with a central server that allows for AI-guided equipment control.
Software Interface and Infrastructure
Adaptive computing is a Python-based software package providing a simple interface to a broad state-of-the-art surrogate modeling capability. The application-agnostic interface allows the user to initialize, improve, save, and recall surrogate modeling hierarchies. Model training can be driven by accuracy thresholds and/or data acquisition budgets. A variety of surrogate model types are available for selection, along with sampling and resource usage strategies. A key novelty of this infrastructure is the ease of use on new applications, enabling intuitive access for application experts to state-of-the-art sampling, modeling, uncertainty management, and data acquisition resources to support optimization, sensitivity, characterization, and control, even in high-dimensional design spaces.

Visual representation of the adaptive computing software framework, which trains surrogate models on multifidelity data, dynamically decides when more data is needed, and schedules acquisition of additional training data across various resources.
Adaptive computing provides application-agnostic support for scale-up and uncertainty management. By design, the software simplifies moving a one-off simulation to a more useful feature-packed tool that can guide higher level decision-making, optimization, and design.
Adaptive computing is modular, application-agnostic, and reusable to enable maximum transferability to new applications and positioned to rapidly deliver state-of-the-art machine learning, uncertainty quantification techniques, and resource management techniques in a cohesive package.
How To License the Software for Research
The adaptive computing software package is copyrighted. For information about how to license this software for your own research, contact Marc Day or Kevin Griffin.
Example Adaptive Computing Framework Applications
The adaptive computing software package has been demonstrated on a range of applications, providing simplified access to modern surrogate and uncertainty quantification strategies that include multifidelity, multiobjective, goal-oriented resource management, combined with active-learning and hierarchical optimization of deterministic and stochastic objectives.
Increased electrification and deployment of secure and robust energy sources require more sophisticated approaches to dynamic system controls that can handle intermittency, balance competing objectives, and ensure reliable grid services. The buildings-specific version of the adaptive computing software is attuned specifically for needs in this application space, providing a modular, scalable, grid-interactive control platform to rapidly design, develop, and prototype control strategies for integrated energy systems. This enables users to simulate, actuate, and control many grid-connected buildings, equipped with integrated AI technologies with real-time adaptation capabilities to optimize system level performance to jointly optimize multiple objectives regarding electrical distribution system level performance and individual building occupant comfort.
For information about how to license the buildings-specific software for your own research, contact Dylan Wald.
AI-accelerated theoretical materials science has made vast advances in prediction of new materials, but rate of prediction has not been matched with simultaneous increase in experimental throughput for complex synthesis methods of inorganic materials.
The adaptive computing framework enables close coupling of experiment and computation through multifidelity surrogate modeling and goal-oriented computing. This method uses adaptive, parallel multidomain searches, exploiting efficient sampling and active learning.
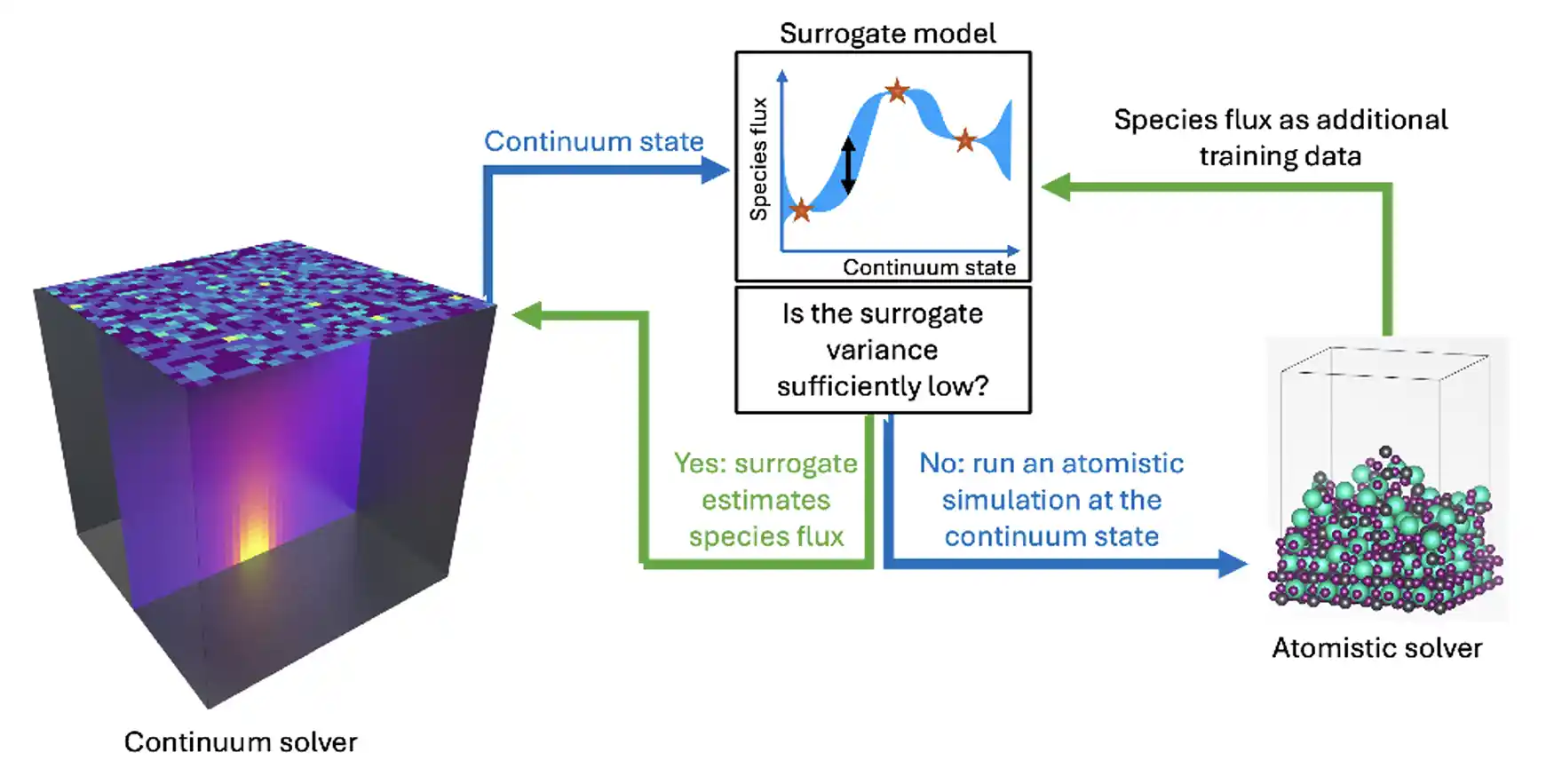
Simulation of gas depositing into a crystal. Adaptive computing decides when it is required to perform expensive atomistic simulations of the crystal or when a fast surrogate model can be used instead.
In coupled multiscale/multisolver simulations, evolving the small-scale physics can be prohibitively expensive and dominate the computational cost. The in-situ ML/AI ROM models supported within the adaptive computing framework can dramatically reduce simulation runtime by constructing uncertainty-aware multifidelity surrogates on the fly in computationally tractable time and using distributed sources for training data acquisition. The figure above illustrates a coupled continuum model for two-component gas-phase mixing to a kinetic Monte Carlo (KMC) model for the growth of a perovskite material surface at the boundary. Here, adaptive computing is used to build and manage a surrogate for the results of a computationally intensive simulation of the surface dynamics as a function of gas phase conditions. Once the initial model is trained, new KMC evaluation points are added to the training set only when sufficiently far from existing data points, based on an error threshold and/or overall computational budget.
In the Degradation Reactions in Electrothermal Energy Storage (DEGREES) project, novel phase-change materials (PCMs) are being evaluated for their capabilities to store and retrieve energy as one key approach to manage intermittent energy demand and generation scenarios. PCMs tend to have extremely low thermal conductivity and may impact corrosion and degradation of the storage vessels and heat transfer components. The DEGREES project explores approaches to evaluate and enhance the performance of PCMs. Although additives can enhance conductivity, impurities transported into the heat exchanger volume from the container walls can degrade system performance over time. Atomistic models are used to estimate properties at the continuum scale, but these are computationally intensive. Surrogate models supported by the adaptive computing framework provide on-the-fly estimates of the material properties and their performance in energy storage systems as they evolve over time, along with an estimate of the errors introduced in the surrogate. These models can save enormous computational resources, particularly when available for re-use.
Stochastic simulations (also noisy experiments) must be carried out repeatedly to obtain good estimates of function values. Ideally, we minimize the number of simulation evaluations yet find provably optimal solutions.
ASTRO-BFDF, part of the adaptive computing framework, adaptively selects where and at what fidelity to sample, how often to resample (to address stochasticity), and when to disregard low-fidelity models—maximizing sample efficiency while ensuring reliable function estimates.
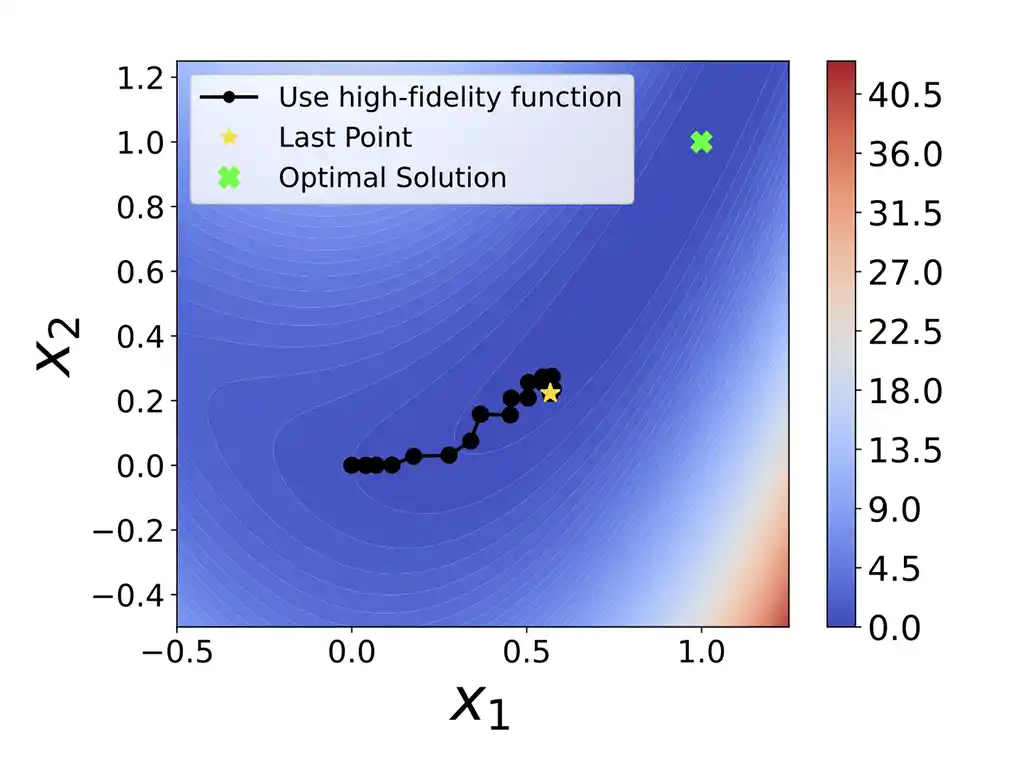
Given a computational budget, using only the high-fidelity simulation to guide the search for the optimum (green cross) leads to suboptimal results.
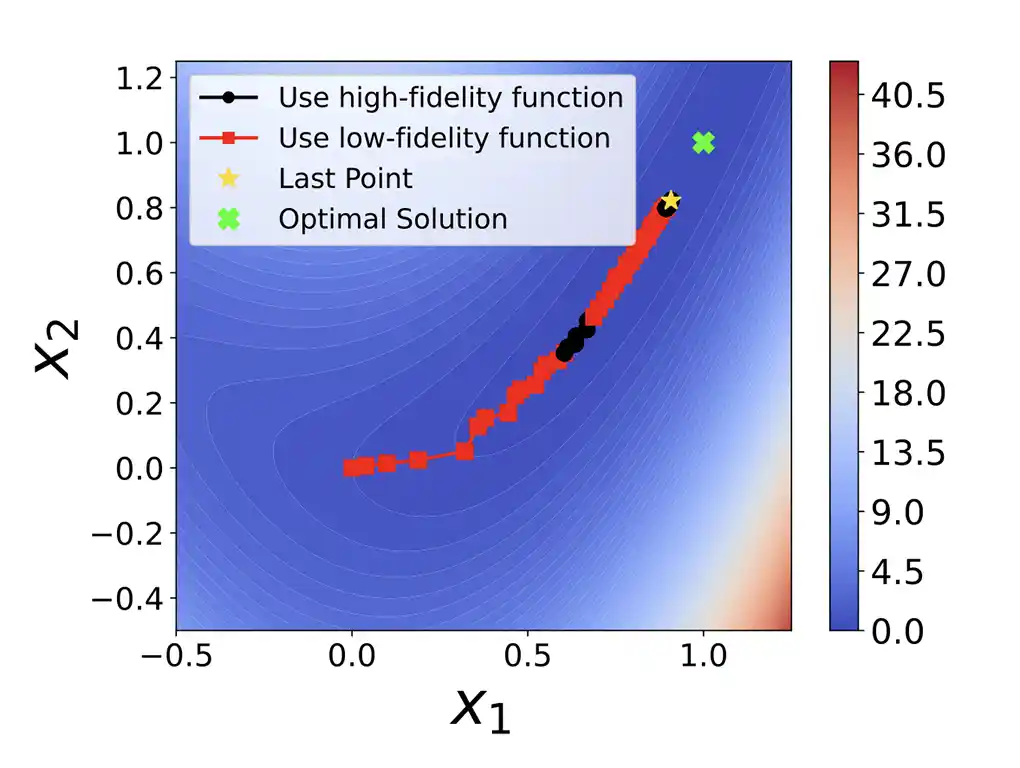
Using the same computational budget, but distributed between low- and high-fidelity evaluations, we can get significantly closer to the true optimum, as the low-fidelity model helps steer the search in the right direction.
Publications
SWR-24-106: Adaptive Computing Shared Software Stack, NLR Software Record (2024)
A Neural-Network-Enhanced Parameter-Varying Framework for Multi-Objective Model Predictive Control Applied to Buildings, Energy and AI (2025)
Adaptive Computing for Scale-Up Problems, Computing in Science & Engineering (2025)
Adaptive Computing: Derivative-Free Optimization in the Context of Distributed Computing and Resource Constraints, SIAM Conference on Computational Science and Engineering (2025)
Adaptive Computing: High Resolution Simulation at Low Resolution Cost, Computational Research in Boston and Beyond Seminar (2024)
Enabling Scale-Up Through Multi-Fidelity Adaptive Computing, INFORMS Optimization Society Conference (2024)
Development Team
NLR's adaptive computing development team includes Principal Investigator Marc Day, Co-Principal Investigator Juli Mueller, Kevin Griffin, Olga Doronina, Hilary Egan, Marc Henry de Frahan, Ryan King, Jibo Sanyal, Deepthi Vaidhynathan, , Rohit Chintala, and Dylan Wald. External contributors include Yunsoo Ha, Janelle Domantay, and Aidan Rivar.
NLR's applications contributors include, Hari Sitaraman, Ross Larsen, Ethan Young, Davi Marcelo Febba, , Andriy Zakutayev, and Nicholas Wimer. External contributors include Daniel Abdullah, Grace Wei, Stephen Shaefer, Geoff Brenecka, and Garritt Tucker.
Contacts
Share
Last Updated Dec. 4, 2025